
Meet Subpart W emissions compliance with automated data integration
H. Qin, Wood Group Mustang, Houston, Texas
On October 30, 2009, the US Environmental Protection Agency (EPA) published the Mandatory Reporting of Greenhouse Gases Rule (referred to as 40 CFR Part 98), which requires reporting of greenhouse gas (GHG) data and other relevant information from large sources and suppliers in the US.
To meet this compliance requirement, reporters/business owners must report true, accurate and complete GHG emissions to the best of their knowledge (according to GHG CFR §98.4 authorization and responsibilities of the designated representative). Calculation methodology is specified in the rule, which makes the quality of the input data critical in ensuring the ultimate reporting quality.
This GHG reporting rule requires an unprecedented amount of data input from oil and natural gas producers. The environmental groups in each organization charged with collecting, calculating and reporting the emissions data are overwhelmed by the task. As an example of volume collected, one ongoing project has estimated 1.2 MM data points for a reporting entity with approximately 9,000 well sites, averaging about 130 data elements per well site. The data required for the GHG natural gas production has been estimated to be approximately two orders of magnitude more than any previous EPA required report.
According to recent EPA public GHG emissions data, there are more than 500 onshore facilities in the US conducting production, processing, transmission and distribution activities. A facility can contain hundreds or thousands of well pads and their equipment in a single hydrocarbon basin (per 40 CFR §98.238). The onshore segment is the largest contributor of facilities, with the necessary reporting criteria of emissions greater than 25,000 metric tons of carbon dioxide equivalent (CO2e). Among the prominent components of the GHG reporting program is Subpart W, dealing with the CO2-equivalent emissions from the producing wellhead through transmission, storage and distribution mains.
The initial Subpart W reporting excluded gas gathering lines and boosting stations prior to the gas processing phase. These systems move natural gas from the well to either larger gathering pipeline systems or to natural gas processing facilities. The EPA plans to issue amended rules that are due to take effect by January 1, 2016 for calculating, monitoring and reporting emissions for these additional sources, with 2017 as the first reporting data year.
More than just volume. More challenging than the sheer volume of data is the fact that much of the information is normally tracked by separate functional groups for different purposes. Data sources include:
- Equipment inventory data, such as information on the number of wells and their associated equipment (e.g., engines, compressors and separators) and their attributes (e.g., horsepower)
- Production data, such as gas and condensate production by well
- Operational and activity data, including all well operating-related information, such as well operating hours, engine run hours, well venting for liquids unloading, gas pressure and gas analysis by well
- Other non-system data, including well flowback events with hydraulic fracture, workover activities without hydraulic fracture, horizon and formation information, etc.
Most of these data are hosted in different formats and systems. In addition, these data do not share the same terminology due to their intended functionalities. Environmental groups within the organization must resolve how to make different data sets talk in a common language. Prior to initiation of the GHG reporting rule, there had not been a pressing need to thread the data to make a united and congruent delineation about assets at the well level.
Rule section §98.237 states that records must be retained. Among the required records is one explaining how company records, engineering estimation or best available information are used to calculate each applicable parameter under this subpart. This requirement stipulates that business owners/reporters must provide a consistent and systemic approach to make assumptions when data discrepancies or gaps exist. This specifically addresses the importance of data quality assurance (QA) and quality control (QC) in collection, integration and reporting.
How to comply. To comply with EPA regulations, particularly with Subpart W, natural gas producers have turned to a centralized data warehouse. This solution automates data collection, integration and quality assurance. It first requires integration of available data from multiple function groups with different terms and reporting formats. Once accomplished, it is necessary to find a unique identifier to make data from multiple systems communicate in a common language.
According to the case study implemented for an ongoing project of a major producer, 80% of the labor time has been spent on data collection, integration and data QA/QC.
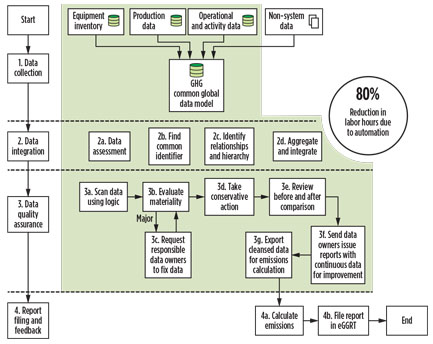
Fig. 1 shows a workflow for GHG reporting preparation. It also demonstrates the four-stage process when data collection, data integration and data QA/QC are automated.
 |
|
Fig. 1. Workflow diagram of GHG reporting preparation. |
Data collection. The main objective of this process stage is to identify sources that could provide data required by the GHG reporting rule. It is not uncommon for these data sources to be from completely disparate systems. However, the focus at this step is to make sure data from these systems can be bridged into a centralized database. In the example shown in Level 1 of the diagram, it is labeled “GHG common data model” for further aggregation and integration. More detailed assessment of which data fields are necessary to integrate will be conducted in the next stage, data integration.
Data integration. The role of data integration is to select all relevant parameters/information and rearrange them into the structure where all data QA/QC and emissions calculations can be performed on the common data platform. These actions lay the foundation for the subsequent process of data QA.
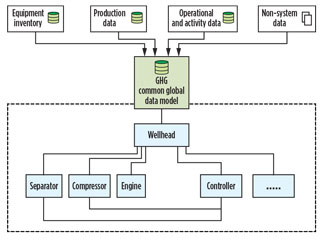
Data integration involves four steps. The first step assesses which data fields need to be integrated, and identifies the primary fields. This requires mastery of the rule requirements and detailed analysis of available data, their applicable ranges and their limitations. Some data may be the direct input of the emissions calculation, and some may be indirect input data. The second step finds the common identifier that connects data pieces from different systems. The common identifier could be embedded in a data field or even in additional mapping, but this is the most essential step.
 |
|
Fig. 2. Equipment relationship within the GHG data model. |
The third step recognizes hierarchical or non-hierarchical relationships between data points. For example, equipment covered by the reporting data requirements, such as pneumatic pumps, engines, compressors, etc., can be mapped hierarchically to the well head at the well site, while the engine-driven compressor to its engine is a typical horizontal, or non-hierarchical, relationship. Once the relationship is established, the data aggregation and integration become easy. The fourth and final step is the actual process of data aggregation of all annual gas production, activity and equipment organized by each well.
Quality assurance (data QA/QC). The quality assurance process is perhaps the most significant action, tying directly back to the CFR §98.4 mandate. It ensures that the reporter meets the compliance requirement that the report is true, accurate and complete. This process can be the largest and most critical time investment of all the processes in preparing the report when the following criteria are met:
- Two or more disparate data systems are involved and were not designed for environmental reporting
- Two or more geographic assets are involved, with more than 1,000 wells in total to report
- There is no standard guideline pertaining to the data tracking in either system
- Rigorous data entry is lacking in either data system.
All of these factors lead to incomplete, inconsistent and discrepant information.
The highest level of QA/QC requires a unique skill set. Combining upstream engineering knowledge and data analysis skills in the data validation of an ongoing project has proven to be a high-yield exercise. Leveraging what data has been integrated from previous processes, a series of business logics was developed to perform data analyses and data validation. These logics are compiled in the format of database scripts within the common data model to perform several functions:
- Check individual system for duplicates, missing key information or discrepancies within its own dataset
- Cross-check well list between equipment inventory, activity and production data systems
- Cross-check well and equipment operating status between equipment inventory, activity and production data systems
- Cross-check equipment count based on their relationships with one another.
In the project mentioned earlier, environmental personnel can easily perform data QA/QC and generate a validated dataset that is ready for GHG emission calculation, along with a feedback report of violations, to send to data owners.
Report filing and feedback. The final stage uses the output from the previous QA/QC process, submits the report to the EPA after emissions calculation, and sends the data issue report to data owners for review and correction. This process takes the remaining 20% effort of the full reporting preparation.
The project mentioned earlier focused on automating the 80% effort. The efficiency that automation provides to the environmental personnel is significant. Processes that once required six weeks of labor have dropped to one or two hours of labor for this large gas producer with 1.2 MM data points. In addition, it provides a comprehensive and transparent methodology to answer the requirement of rule section CFR §98.237 that records must be kept to explain how best available information or engineering estimates are used to calculate emissions.
Benefits extend beyond the GHG reporting rule for Subpart W production. This applies to the imminent Subpart W for gas gathering. More importantly, with the feedback reports of data issues to data owners, it creates a closed loop to drive for more consistent and accurate data for environmental reporting and for other business-related analysis. The long-term benefits deserve to be noted.
Recommendations. The EPA has continued to increase its emissions data requirements and number of regulations. Additionally, they are scrutinizing submitted data for consistency, with a focus on validation. As noted in the case of a major US producer, the solution involved the automation of data collection.
Quality assurance is a key component of the solution, coupling a skill set of upstream engineering knowledge with a modular database system design, systems integration and data analysis expertise. The systematic approach and consistent QA/QC methodology aligns data with EPA reporting requirements, helping ensure regulatory requirements.
The ultimate solution dramatically reduces labor time and increases efficiency. Data is reusable for other federal and state agencies, avoiding unnecessary duplication of effort. Additionally, the data accuracy allows the environmental staff to further analyze operating data for maximizing production while minimizing air emissions. GP
Hong Qin has more than 15 years of experience in the software and professional services industry. She has held leadership roles in multiple air emissions projects, including recent work focused on developing advanced GHG solutions. Ms. Qin is a civil engineering graduate of the Harbin Institute of Technology in China and holds a master’s degree in industrial engineering from the University of Houston in Texas. She is a certified PMP member of the Project Management Institute.


Comments